
Interpreting vision models with sparse dictionary learning: a case for hierarchical learning
Recently, Anthropic demonstrated the power of sparse dictionary learning as an interpretability tool in a large language model. They applied the method to a single embedding layer of a large network to identify a basis of more interpretable features, and demonstrated control of the model output by activating the combination of neurons responsible for single, interpretable features. The work shows that the model is knowledgeable in a meaningful way, but that the meaning is hard to discern in the lower-dimensional neuron basis. By identifying a more interpretable, higher-dimensional basis, Anthropic researchers lay the groundwork to establish whether the model learned desired relationships and tailor fine-tuning and model controls accordingly.
This is an exciting result for AI interpretability, and one that would be great to extend to other important models. In this post I want to think through applying the sparse dictionary learning method to a computer vision model.
There are a few major differences in the data used to train computer vision and large language models (beyond the obvious pictures vs. sentences). In language models, training data are sentences and phrases that contain concepts and relationships among those concepts. In image foundation models, data are images and their associated class labels. Images and their labels are not organized in any conceptual or hierarchical structure. Where a language model will easily learn that a human is a type of mammal, the path for a vision model to learn this concept hierarchy is not so simple.
Because most major computer vision models lack a sense of concept hierarchy, I believe that directly applying sparse dictionary learning is not the right next step to uncovering controllable, interpretable features in common vision models. I will briefly articulate why and what we can do about it.
Assumptions
- Sparse dictionary learning reveals concepts that a model has learned in training. In order to reveal it, the model must know it.
- The model needs to have learned complex conceptual relationships within and across data instances. In order to learn relationships, the model must be trained with relational data.
- Vision foundation models are useful, but do not learn concept hierarchy or logical entailment.
A model that is trained without concept hierarchy will not learn the generalizable concepts that would be uncovered by sparse dictionary learning. Fortunately, vision-language models like CLIP introduce some weak concept hierarchy from language captions, and a few recent works demonstrate training methods that optimize hierarchical understanding.
To best leverage the sparse dictionary learning method in vision models and improve interpretability and control, it should be applied to a computer vision model that has been optimized for hierarchical consistency.
Vision models differ from LLMs
LLMs are trained with concept hierarchies and a sense of logical entailment, where vision models are trained by repetition across large collections of images and their labels. In vision model training, we don’t consider relationships of the objects within or between images.
The largest generative language models demonstrate hierarchical consistency and readily generalize to unseen phrases. In contrast, foundational vision models like AlexNet, ImageNet and even SAM are known to rely on spurious correlations, generalize poorly to unseen data and to lack both intra- and inter-image hierarchical consistency.
SAM is one of the most powerful vision models available today, but it lacks intra-image hierarchical consistency. In the figure below, reproduced from Figure 6 of Learning Hierarchical Image Segmentation For Recognition and By Recognition, SAM correctly identifies a fishing scene, but semantically gives the label ‘fish’ to both the man and fish in the image.
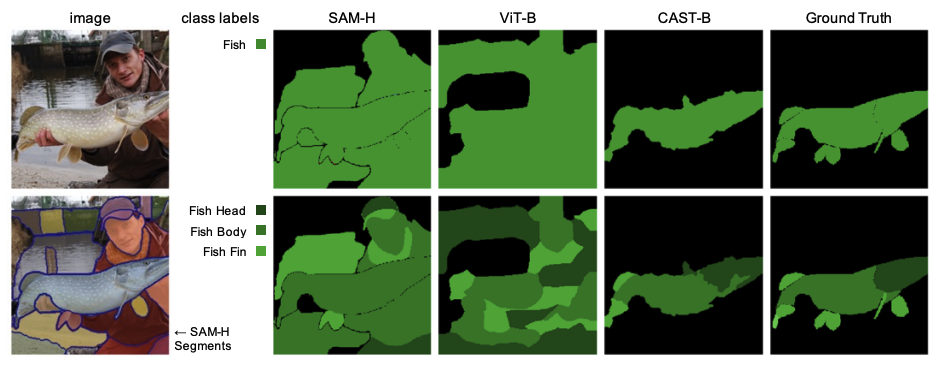
Using sparse dictionary learning to uncover meaningful features relies on the model containing enough of them. While it’s clear that vision models encode useful information, it may be more difficult to extract and interpret than in sentence encoders that are directly optimized with logical entailment and concept hierarchy.
Vision models can be trained with concept hierarchy
I hope that by now I have established that sparse dictionary learning is an excellent tool for interpretability and control of AI models, but that it may not readily apply to common vision models due to fundamental differences in how LLMs and vision models learn and generalize.
Understanding and implementing concept hierarchies and logical entailment in vision models is an active area of research. In their work, Emergent Visual-Semantic Hierarchies in Image-Text Representations (ECCV 2024), M. Alper and H. Averbuch-Elor studied emergent concept hierarchy in the CLIP model, introduced a metric to quantify it, and fine-tuned the model on this metric to produce the “RE-CLIP” model, with quantitative and qualitative improvement to concept hierarchy and inter-image consistency in the model’s latent representations.
The CAST model was introduced at ICLR 2024 in Learning Hierarchical Image Segmentation For Recognition and By Recognition, by Tsung-Wei Ke et. al. Authors train CAST by enforcing hierarchical consistency across increasingly large superpixels within an image, thereby enforcing intra-image consistency. The CAST model has the advantage of being a relatively lightweight while outperforming CLIP in important tasks like semantic segmentation.
Conclusion
Sparse dictionary learning is a promising interpretability tool, but it assumes that a model has learned general concepts. Common vision models that generalize poorly to unseen data may not contain sufficient general knowledge for sparse dictionary learning to effectively identify interpretable, monosemantic features.
In this post I’ve laid out a hypothesis that applying dictionary learning to a vision model trained for hierarchical understanding, will be more likely to uncover controllable, interpretable features.
To test this effectively would require first quantifying hierarchical consistency in both a common vision model, like ImageNet or CLIP, and in one of the models optimized for hierarchical consistency, CAST or RE-CLIP. Next, applying sparse dictionary learning on each. Finally, quantifying which of the models has yielded more interpretable features.